


Starburst Enterprise Platform (SEP) was the go-to engine for federated queries and analytics at scale. We used it to query across data lakes, warehouses, and relational stores without moving data.
But ETL and pipeline building? That typically lived elsewhere Spark clusters, Pandas scripts, or licensed ETL tools.
Recently, while going through a set of blogs from Starburst and Lester Martin, I realised something powerful: with the new Python DataFrame APIs, even ETL and pipeline workflows can be done natively in Starburst Enterprise.
What I Learned About Python DataFrames in SEP?
SEP now supports two major Python DataFrame APIs on top of Trino:
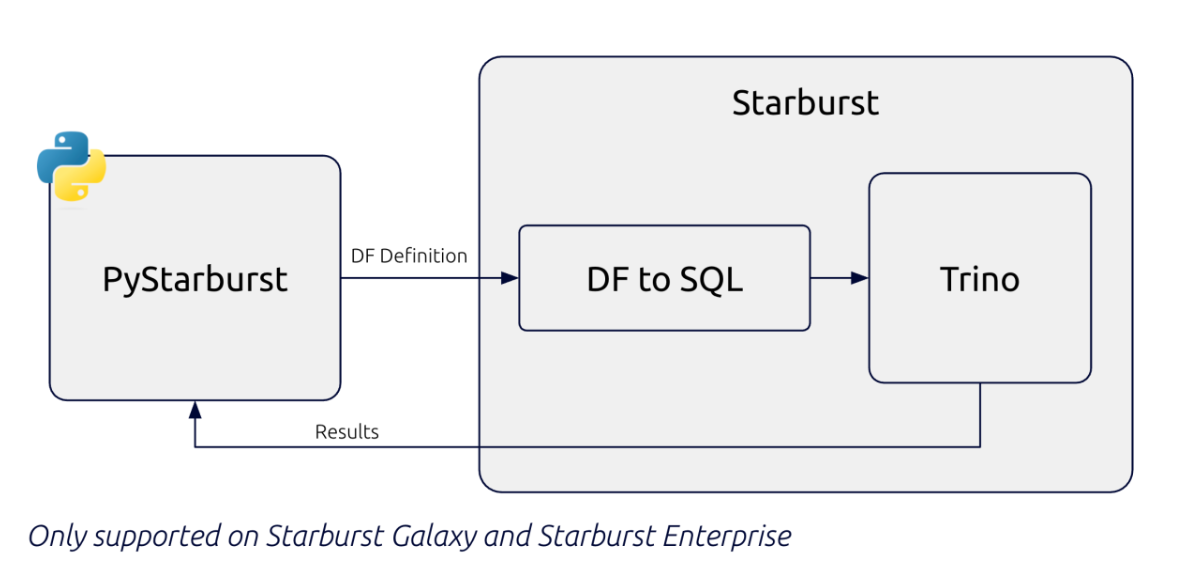
PyStarburst: Starburst’s native DataFrame API designed to feel familiar to PySpark users. It leverages Starburst-native extensions for performance.
Ibis: A backend-agnostic DataFrame API that works across multiple engines, including SEP, providing portability and flexibility in hybrid data landscapes.
ETL Without Moving Data?
Instead of extracting data into external tools:
You can read tables directly from ADLS, S3, or your warehouse into a Python DataFrame inside SEP.
Apply transformations using intuitive Python methods like filters, joins, and group-bys.
Save the transformed results back to object stores, registered as Hive or Glue tables.
All of this happens inside Starburst Enterprise natively , no extra data movement or cluster hops required.
Pipelines That Are Enterprise-Ready
Lazy execution: Transformations don’t run immediately; like in Spark, they only execute when you call
.collect()or save results.SEP’s orchestration and resource management capabilities allow scaling to production workloads.
Integration with popular schedulers like Airflow, dbt, and CI/CD pipelines allows treating SEP as a fully-fledged pipeline engine.
This means development teams can write, test, version, and deploy ETL pipelines as regular Python projects unlocking developer discipline alongside enterprise governance.
PyStarburst vs Ibis in Enterprise Context
PyStarburst is ideal if you are fully invested in SEP and want the best performance with Starburst-native features.
Ibis shines if your enterprise environment involves multiple SQL engines and you want a portable DataFrame API across platforms.
Why This Stands Out
In my experience with enterprise data platforms, there’s often a fragmented ecosystem:
SEP for federation and analytics.
Spark clusters for ETL.
Low-code tools (like Alteryx) for smaller jobs.
This results in complexity, silos, and governance headaches.
SEP’s Python DataFrame APIs reveal a future where:
One engine queries, transforms, and serves pipelines.
Governance happens in a single place, backed by Hive metastores.
The operational burden and complexity drastically reduce.
Closing Thought
With Python DataFrames, Starburst Enterprise is evolving beyond analytics into a unified pipeline platform. ETL and transformations no longer need separate clusters or tools they can run directly on the same governed, federated platform.
For me, SEP now looks less like a query engine and more like a unified data platform , one that simplifies pipelines, governance, and analytics in a single place
References :